
Web scraping & machine learning steam project
My second Metis data science project is now in the books. I ended up scrapping a database of just under 7000 Steam computer games. That data required a great amount of cleaning. Missing data, more missing data, irregular hand entered date entries, a couple dozen other formatting problems, generating features to split up or concentrate data columns (splitting up genre into dumby variables, concentrating released languages into a count, etc.). Not to mention converting it all to numerical formats for the machine learning algorithms without white-washing over all the missing data. Ended up with up to 50 variables (features) for each game to work with.
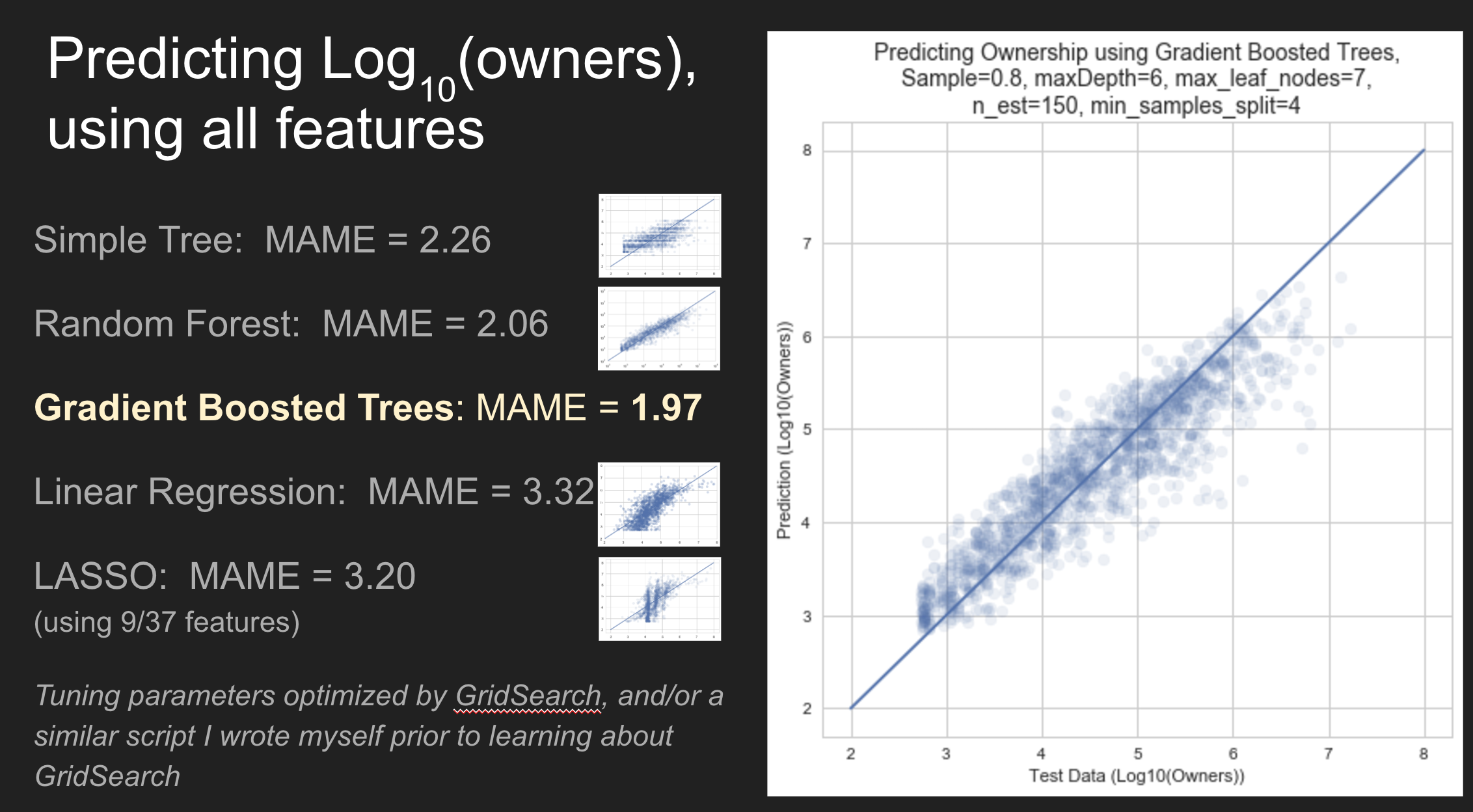
Applying the various machine learning algorithms was relatively easy in compaired to collecting the data, but feature selection proved a little tricky. As it turned out none of my features was even a half-decent predictor of game ownership numbers, and on top of that the ownership numbers spanned from over 100,000,000 to less than 1000, which ment being off by a few % on those popular titles was making my models fit in ways which were far from ideal, and wasn’t resolved till near the end of the project when I switched over to predicting Log10(owners), but as a result had to switch to a logarithmic error function (a mean multiplicative logarithmic error in my case; thanks to Brian for steering me in the right direction on that one!). Since then I have learned that there are quite a few logarithmic error functions used in cases like this, and aren’t all that unusual.
In total I ended up using a simple tree, Random Forrest, Gradient Boosted Trees, Linear Regression, and Lasso algorithms to predict both ownership (log of) and game price (as well as a few for medianplaytime). It turned out the the Random Forrest and Gradient Boosted Trees models were able to do quite a bit better, predicting ownership within about a factor of 2; but only by utilizing a large number of features. I tried several models only utilizing user ratings, reviews, and game age, but they proved very poor in comparison to the tree models. It turned out the tree models (and lasso) were spreading their prediction weights across about half of my features, with none recieving more than a 15% weight, but around 10 between 5 and 15%. Apparently this was a complex problem with a lot of variables of possible importance. I did not have a chance to see how the models reacted to eliminating every feature one by one, there simply was not time with so many features.
My presentation ended up being too long and technical, and not focused enough on my thought process and big picture ideas. I will make sure to keep that in mind in the future. Giving one of these project presentations is quite a bit different than teaching Gauss’s Law! It’s hard not to talk about all the details I spend so much time on though ;-). Below is a link to my presentation if you are interested. There’s a lot more specifics than what I’ve got into here.
Steam Database Machine Learning Project
Today we were briefed on ‘Project McNulty’, the main constraints of which are that we will be making a catagorical classification this time, a SQL database should be used, and we have a lot of freedom were we find our data. I know Support Vector Machines, and several other machine learning algorithms are coming up which will be fun to try out. At this point I haven’t gotten far brainstorming for the project; other than that I am leaning toward using physical data or observations this time around.
Also got access to a small server on Amazon Web Services today. Configuring all these accounts and interfaces feels more challenging than the mathematical or programming aspects of the program thus far. Hopefully that is a good sign.